Hive Basic Commands
by Jung Jaeeun
1. Create Database, Table
하이브에서 데이터베이스를 만든다는 것은 실제 데이터를 저장하는 것이 아니라 테이블의 스키마를 설정하는 것이다. 해당 정보는 metastore에 저장된다.
CREATE DATABASE, CREATE DATABASE IF NOT EXISTS를 활용하여 데이터베이스를 만들 수 있다.
create database d1;
# ignored
create database if not exists d1;
# error
create database d1;
또는 comment, properties 같은 정보를 설정하면서 데이터베이스를 만들 수 있다.
# comment
create database if not exists d2 comment 'this is d2';
# database properties
create database if not exists d3 with db properties('creator'='jaeeun', 'date'='2021-06-23');
# 확인
describe database extended d2;
USE {database}를 통해 데이터베이스에 접근하여 테이블을 생성하거나 조작할 수 있다.
하이브에는 internal, external 두 종류의 테이블이 존재한다. 전자의 경우 하이브가 테이블의 유일한 소유자가 되는 반면 후자에는 하이브가 metastore만 소유하고 실제 데이터는 HDFS가 관리한다. 따라서 DROP을 사용했을 때 external table은 metastore(table definition)만 사라지고 internal table은 metastore, 실제 데이터가 모두 사라진다. 기본값은 internal table이다.
CREATE TABLE, CREATE EXTERNAL TABLE을 통해 테이블을 생성한다.

위와 같은 데이터를 저장하고 싶다면
create table if not exists table1(col1 int,col2 array<string>,col3 string,col4 int)
row format delimited fields terminated by ','
collection items terminated by ':'
lines terminated by '\n'
stored as textfile;
와 같은 쿼리를 사용하면 된다.
테이블은 기본적으로 /user/hive/warehouse 디렉토리에 저장되는데, 이를 바꾸고 싶다면 location '{dir}'을 뒤에 붙여준다.
2. Load Data
이렇게 테이블 포맷을 설정해준 다음, load data inpath를 사용하여 테이블에 데이터를 로딩한다. 만약 파일이 HDFS가 아닌 로컬에 존재한다면 load data local inpath를 사용한다.
load data inpath '/home/ubuntu/table1.txt' into table table1;
into table은 테이블에 데이터가 존재한다면 append 하는 방식으로 동작한다. overwrite table은 테이블에 있는 기존 데이터를 지우고 새롭게 데이터를 쓴다.
3. Insert Statement
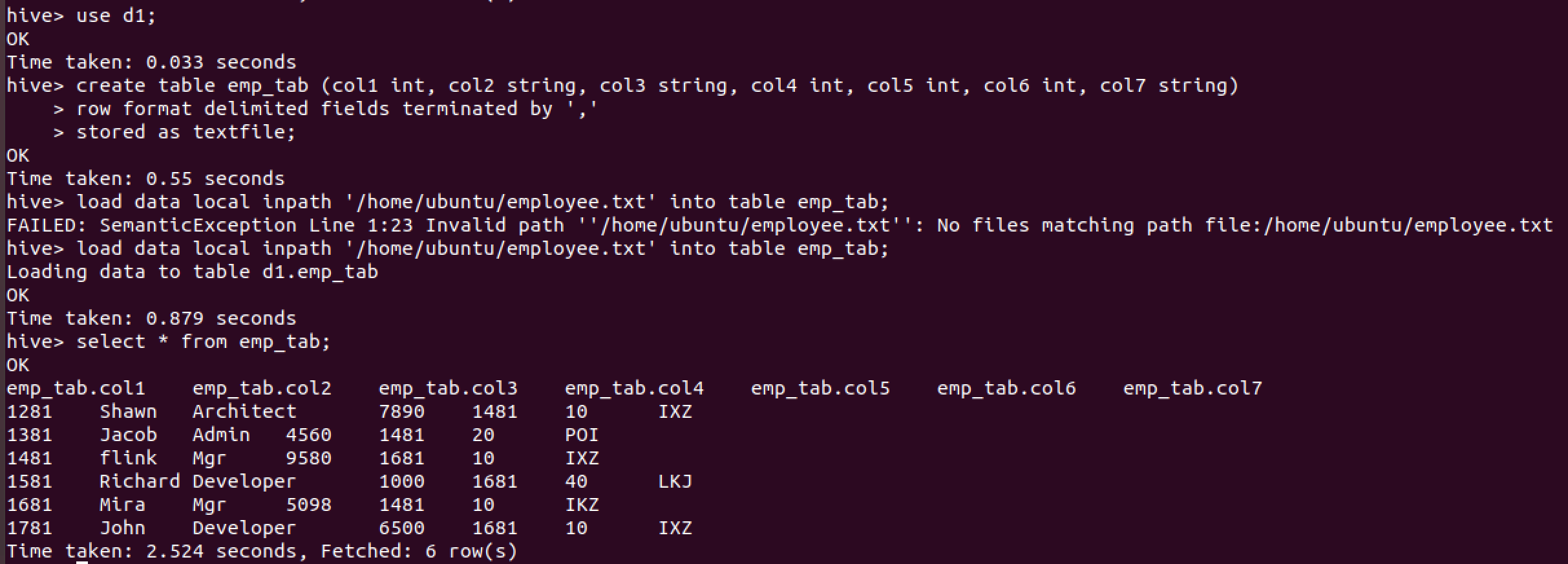
이런 테이블을 만들었다고 가정하자.
create table tab (col1 int, col2 string, col3 string) stored as textfile;
insert into table tab select col1, col2, col3 from emp_tab;
결과는 다음과 같다.
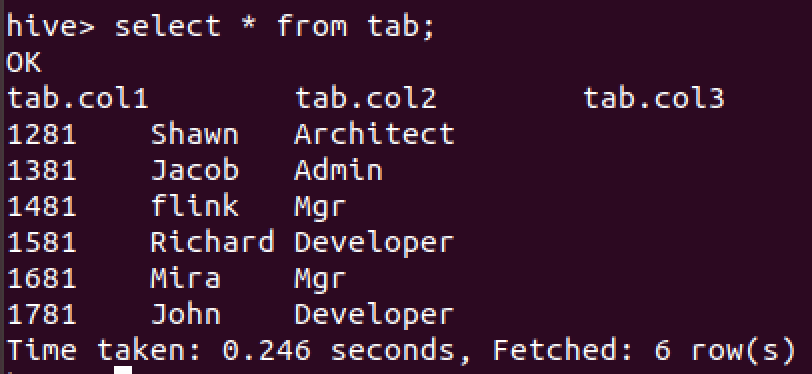
insert overwrite table tab select col1, col2, col3 from emp_tab;
이 쿼리를 사용하면 모든 데이터를 지우고 새로 데이터를 삽입한다.
3-1. Multi Insert
개발자를 위한 테이블과 매니저를 위한 테이블이 따로 존재하는 상황을 생각해보자.
from emp_tab insert into developer_tab select col1, col2, col3 where col3 = 'Developer';
from emp_tab insert into manager_tab select col1, col2, col3 where col3 = 'Mgr';
4. Alter Table
테이블의 스키마를 변경하기 위해 사용한다.
# 컬럼 추가
alter table tab add columns (col4 string, col5 int);
# 컬럼 이름, 순서 변경
alter table tab change col1 col1 int after col3;
# 테이블 이름 변경
alter table tab rename to tab1;
# 컬럼 replace
alter table tab1 replace columns (id int, name string);
# table properties 변경
alter table tab1 set tblproperties ('auto.perge'='true');
# 확인
desc formatted tab1;
# 파일 포맷 변경
alter table tab1 set fileformat avro;
5. Sorting
# ORDER BY
select col2 from tab order by col2;
# SORT BY
select col2 from tab sort by col2;
# DISTRIBUTE BY
select col2 from tab distribute by col2;
# CLUSTER BY
select col2 from tab cluster by col2;
ORDER BY: 데이터를 fully sort 하기 위해 single reducer를 사용한다. 따라서 데이터 크기가 매우 클 때는LIMIT을 사용해야 한다.SORT BY: 여러 개의 reducer를 사용한다. 일반적으로 full sort가 되지 않는다.DISTRIBUTE BY: 겹치지 않는 데이터로 나눈다. 정렬을 하지 않는다. 정렬을 하고 싶다면distribute by col2 sort by col2와 같이 쿼리를 작성해야 한다.CLUSTER BY:DISTRIBUTE BY,SORT BY의 combination이다.
Subscribe via RSS