Hive Basic
by Jung Jaeeun
0. Introduction to Hive
What Hive is?
- 하이브란 HDFS에 저장된 데이터를 SQL과 비슷한 쿼리를 통해 처리할 수 있게 하는 쿼리 툴이다.
- SQL은 DBMS에 저장된 데이터를 다루고, 하이브는 HDFS에 저장된 데이터를 다룬다.
- 테이블로 저장된 구조화된 데이터를 처리한다.
- Batch processing에 적합하다.
- MapReduce와 HDFS를 연결하는 렌즈에 해당한다. 하이브 쿼리는 내부적으로 MapReduce 프로그램으로 변환된다.
- Parquet, sequence file, ORC file, text file 등 여러 파일 포맷을 지원한다.
What Hive is Not?
- 하이브는 데이터베이스가 아니다. HDFS에 저장된 데이터를 tabular manner로 처리할 뿐이다.
- OLTP를 위한 툴이 아니다. Row level insert, update, delete를 지원하지 않는다. 최근 버전은 지원하기 시작했지만 그렇게 효과적이지 않고 지정된 파일 포맷에만 가능하다.
- Latency가 커 실시간 처리에는 적합하지 않다. 쿼리를 MapReduce 프로그램으로 바꿔야 하기 때문이다.
- 이미지, 비디오와 같은 비정형 데이터는 지원하지 않는다.
1. Motivation of Hive
- 하이브는 MapReduce 프로그래밍의 복잡함을 줄이기 위해 개발되었다. Java 개발자가 아닌 사람도 데이터를 분석할 수 있게끔 해준다.
- SQL 지식을 사용해서 하이브 쿼리를 작성할 수 있다.
2. Hive VS SQL
- 하이브는 SQL과 달리 데이터베이스가 아니다. 물리적 데이터를 저장하는 것은 HDFS이다.
- Write-Once, Read-Many concept로 만들어진 프로그램이다. (SQL은 Write-Many, Read-Many)
- 하이브는 OLAP 시스템에 적합하고 SQL은 OLTP 시스템에 적합하다.
- 하이브는 SQL에 비해 scalable 하다.
2. Trailer

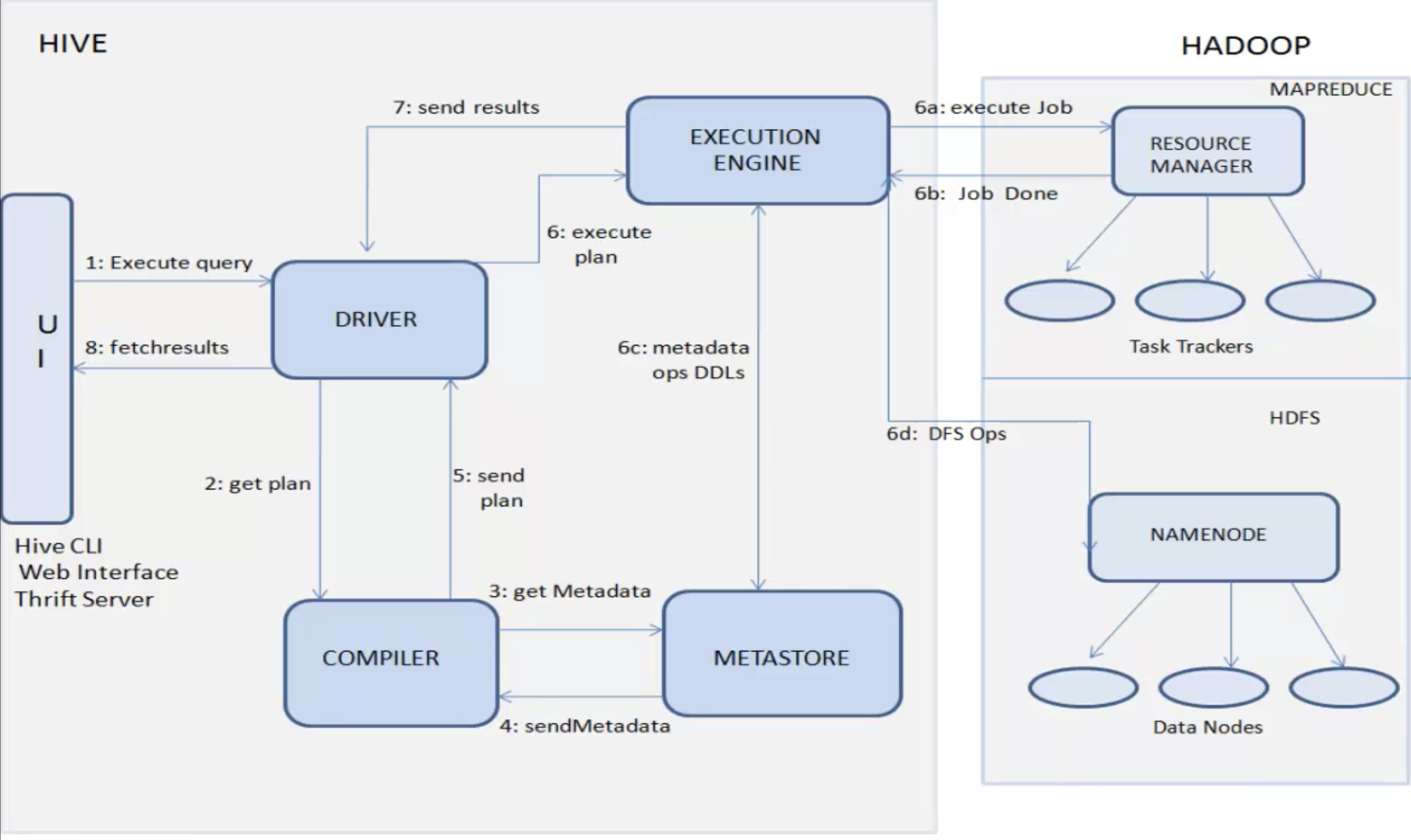
위는 하이브가 작동하는 방식을 그림으로 나타낸 것이다. Create table 문을 이용하여 HDFS 파일을 테이블 데이터로 인식한다. 이를 Loading 과정이라고 하는데, 실제 데이터는 변하지 않고 하이브가 그렇게 인식할 뿐이다. Loading이 끝나면 쿼리를 실행할 수 있다.
3. Installation
나는 링크1, 링크2를 참고하여 가상 머신에 하둡, 하이브를 설정했다.
Subscribe via RSS